Wat is Undersampling?
Een techniek waarbij je bewust minder data uit de grootste groep gebruikt, zodat je AI-model niet leert om alleen die ene grote groep te voorspellen — handig bij scheef verdeelde datasets.
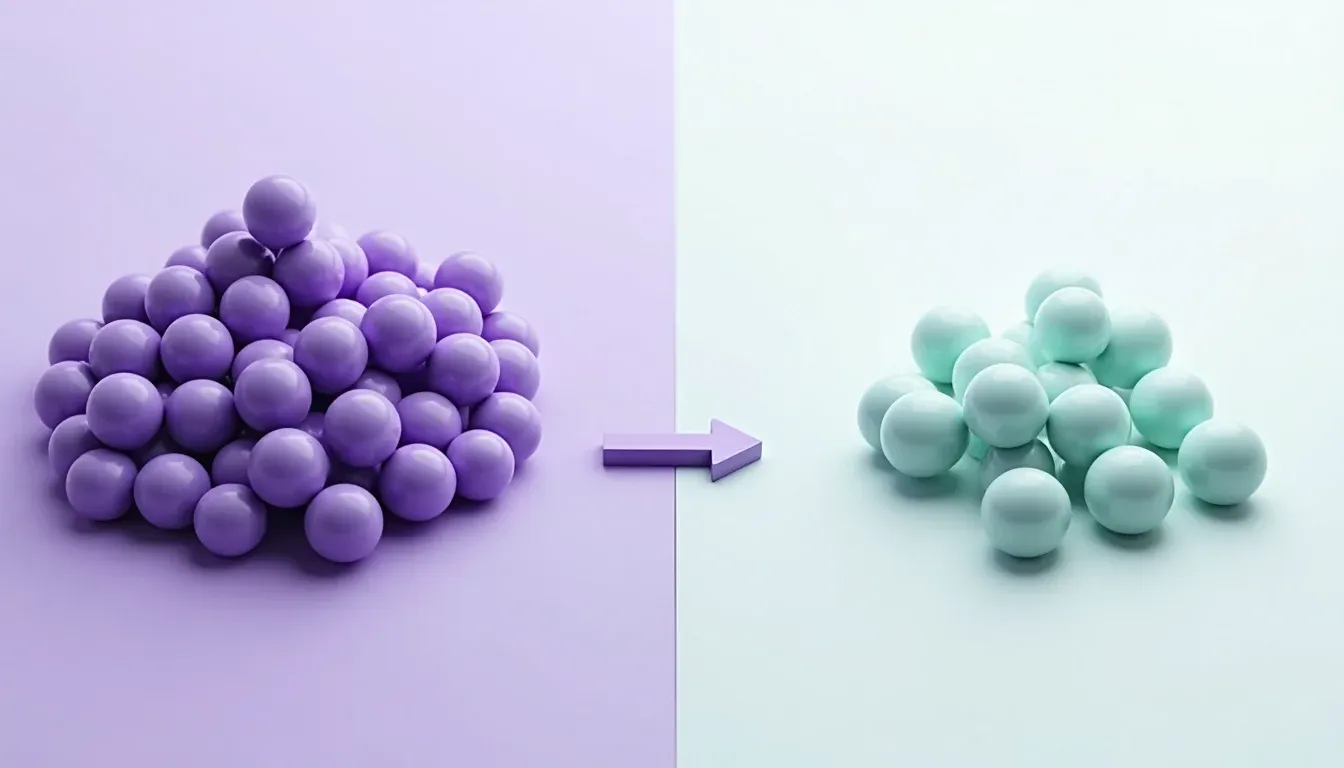
Wat is undersampling?
Stel je voor dat je een AI-model traint om fraude te herkennen in banktransacties. Van de 100.000 transacties in je dataset zijn er maar 500 frauduleus — de rest is legitiem. Als je je model gewoon op die data loslaat, leert het een luie truc: "zeg gewoon altijd dat het geen fraude is", want in 99,5% van de gevallen klopt dat. Handig voor de score, maar nutteloos in de praktijk.
Undersampling lost dit op door bewust minder data uit de grote groep te gebruiken. In dit geval gooi je het grootste deel van de legitieme transacties weg, zodat je bijvoorbeeld 500 fraudegevallen overhoudt én 500 normale transacties. Nu is de verhouding 50-50, en moet het model écht leren onderscheiden — niet gewoon gokken op de grootste groep.
Het is het tegenovergestelde van oversampling, waar je juist de kleine groep kunstmatig vergroot door voorbeelden te dupliceren of te genereren.
Waarom zou je dit doen?
In de praktijk zijn veel datasets onevenwichtig verdeeld. Denk aan:
Ziektes die maar bij 1% van de mensen voorkomen
Klikken op advertenties (vaak <5% van de vertoningen)
Defecte producten in een fabriek (hopelijk zeldzaam)
Spam in e-mail (varieert, maar vaak minder dan 10%)
Als je model alleen leert om "nee" te zeggen, scoort het hoog op nauwkeurigheid maar mist het precies de gevallen waar je het voor bouwt. Undersampling dwingt het model om genuanceerder te kijken.
Het nadeel? Je gooit data weg. Soms veel data. Dat kan pijn doen als je weinig voorbeelden hebt, want elk voorbeeld bevat potentieel waardevolle patronen. Het risico is dat je model niet de volle variatie van "normale" gevallen leert kennen.
Hoe werkt het in de praktijk?
De eenvoudigste vorm: random undersampling. Je pakt willekeurig een subset van de grote groep, net zo groot als de kleine groep. Klaar.
Verder kun je kiezen voor:
Tomek Links — verwijder voorbeelden uit de grote groep die vlak bij de grens met de kleine groep liggen, zodat de scheidslijn helderder wordt
Near Miss — selecteer voorbeelden uit de grote groep die het dichtst bij de kleine groep staan, zodat het model leert met de moeilijkste gevallen
Cluster-based undersampling — groepeer de grote groep in clusters en neem uit elk cluster een representatief voorbeeld, zodat je diversiteit behoudt
In de praktijk combineer je undersampling vaak met andere technieken: een beetje undersampling, een beetje oversampling, en misschien aangepaste gewichten voor de klassen tijdens training.
Waar kom je het tegen?
Undersampling wordt toegepast in vrijwel elke AI-toepassing waar de uitkomst scheef verdeeld is:
Fraudedetectie — banken, verzekeraars, webwinkels
Medische diagnostiek — zeldzame ziektes herkennen in CT-scans of bloedonderzoek
Kwaliteitscontrole — defecten vinden in productielijnen
Churn-voorspelling — welke klanten gaan binnenkort weg?
Sentiment-analyse — als 95% van de reviews positief is, wil je toch de negatieve kunnen herkennen
In Python-bibliotheken zoals imbalanced-learn vind je kant-en-klare implementaties. Ook in AutoML-tools (zoals H2O, DataRobot) wordt undersampling soms automatisch toegepast als de tool een onevenwichtige dataset detecteert.
Wanneer wél, wanneer niet?
Gebruik undersampling als je veel data hebt in de grote groep en je het je kunt veroorloven om voorbeelden weg te gooien. Het is snel, simpel en effectief.
Kies iets anders als je weinig data hebt, of als de variatie binnen de grote groep cruciaal is. Dan is oversampling of het aanpassen van class weights tijdens training vaak veiliger.
Soms is het slim om beide te testen: train een model met undersampling, een met oversampling, en vergelijk welke beter presteert op je validatieset. Dat is uiteindelijk de enige manier om zeker te weten wat werkt voor jouw specifieke dataset.
Heb je een AI-model dat altijd dezelfde uitkomst voorspelt? Check of je dataset scheef verdeeld is. Undersampling kan het model dwingen om genuanceerder te kijken — en daarmee bruikbaarder te worden in de praktijk.
Veelgestelde vragen over Undersampling
De drie meest gestelde vragen over dit onderwerp, kort beantwoord.
Wat is Undersampling?
Een techniek waarbij je bewust minder data uit de grootste groep gebruikt, zodat je AI-model niet leert om alleen die ene grote groep te voorspellen — handig bij scheef verdeelde datasets.
Waarom is Undersampling belangrijk?
Stel je voor dat je een AI-model traint om fraude te herkennen in banktransacties. Van de 100.000 transacties in je dataset zijn er maar 500 frauduleus — de rest is legitiem. Als je je model gewoon op die data loslaat, leert het een luie truc: "zeg gewoon altijd dat het geen fraude is", want in 99,5% van de gevallen klopt dat. Handig voor de score, maar nutteloos in de praktijk.
Hoe wordt Undersampling toegepast?
Undersampling lost dit op door bewust minder data uit de grote groep te gebruiken. In dit geval gooi je het grootste deel van de legitieme transacties weg, zodat je bijvoorbeeld 500 fraudegevallen overhoudt én 500 normale transacties. Nu is de verhouding 50-50, en moet het model écht leren onderscheiden — niet gewoon gokken op de grootste groep.